Abstract
We introduce AnySplat, a feed‑forward network for novel‑view synthesis from uncalibrated image collections. In contrast to traditional neural‑rendering pipelines that demand known camera poses and per‑scene optimization, or recent feed‑forward methods that buckle under the computational weight of dense views—our model predicts everything in one shot. A single forward pass yields a set of 3D Gaussian primitives encoding both scene geometry and appearance, and the corresponding camera intrinsics and extrinsics for each input image. This unified design scales effortlessly to casually captured, multi‑view datasets without any pose annotations. In extensive zero‑shot evaluations, AnySplat matches the quality of pose‑aware baselines in both sparse‑ and dense‑view scenarios while surpassing existing pose‑free approaches. Moreover, it greatly reduce rendering latency compared to optimization‑based neural fields, bringing real‑time novel‑view synthesis within reach for unconstrained capture settings.

key contributions
- Feed-forward reconstruction and rendering. Our model takes uncalibrated multi-view inputs and simultaneously predicts 3D Gaussian primitives and their camera intrinsics/extrinsics, delivering higher‐quality reconstructions than prior feed-forward methods, and even outperforming optimization-based pipelines in challenging scenarios.
- Efficient self-supervised knowledge distillation. We distill geometry priors from a pretrained VGGT model via a novel, end-to-end training pipeline, without any 3D annotations, unlocking high-fidelity rendering and enhanced multi-view consistency in under one day on 8–16 GPUs.
- Differentiable voxel-guided Gaussian pruning. Our custom voxelization strategy eliminates 30–70% of Gaussian primitives while preserving rendering quality, yielding a unified, compute‐efficient model that gracefully handles both sparse and dense capture setups.
Method
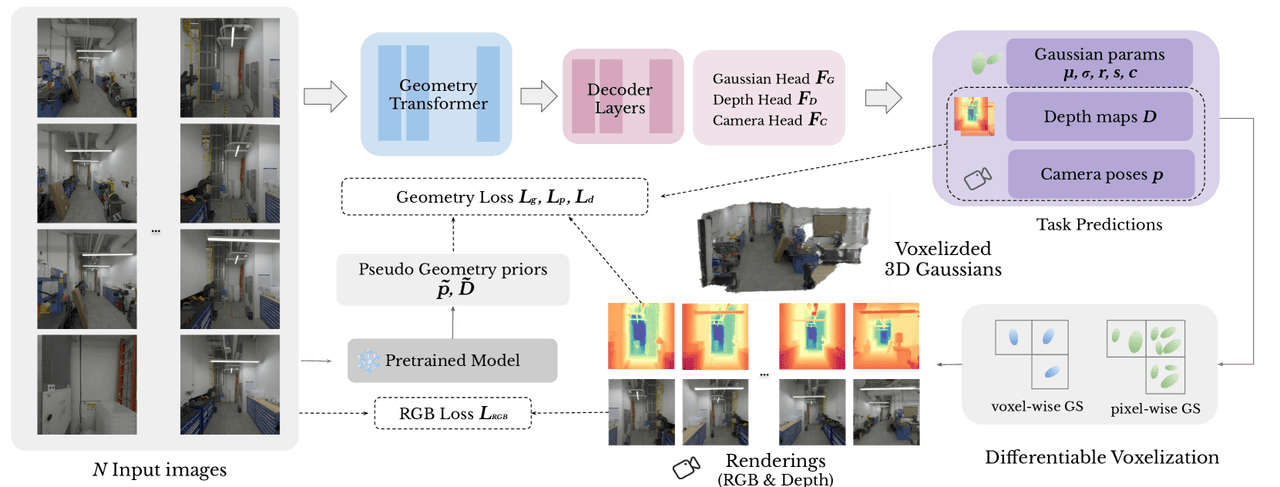
In this work, we introduce AnySplat, a feed-forward 3D reconstruction model that integrates a lightweight rendering head with our geometry-consistency enhancement, augmented by a self-supervised rendering proxy and knowledge distillation. We view this as a novel way to fully unlock the potential of 3D foundation models and elevate their scalability to a broader scope. Our experiments demonstrate AnySplat’s robust and competitive results on both sparse and dense multiview reconstruction and rendering benchmarks using unconstrained, uncalibrated inputs. Additionally, the model training remains efficient, requiring minimal time and compute, enabling feed-forward 3D Gaussian Splatting reconstructions and high-fidelity renderings in just seconds at inference time. We expect this low-latency pipeline to open new possibilities for future interactive and real-time 3D applications.Despite its improvements, AnySplat still observe artifacts in challenging regions, such as skies, specular highlights, and thin structures; its reconstruction-based rendering loss may be less stable under dynamic scenes or varying illumination, and the compute–resolution trade-off (i.e., number of Gaussians scaling alongside input and voxel resolution) can slow performance when handling very high resolution or large numbers of views. Future work should incorporate more diverse real‑world captures and high‑quality synthetic datasets, featuring varied camera trajectories and scene complexities from object‑centric to unbounded environments. On the technical side, enhancing patch‑size flexibility, improving robustness to repetitive texture patterns, and streamlining the scaling to thousands of high‑resolution inputs, especially paired with rapid advances in mobile capture technology, offer particularly promising directions.